Z-Image ControlNet 姿态/深度/线稿控制指南
掌握三种核心结构控制模式,让 AI 图像生成既遵循你的构图意图,又保持模型原生风格。
一、引言:ControlNet 如何分离"风格"与"结构"
在 AI 图像生成中,一个永恒的难题是:如何让模型既听话(遵循你的构图),又不失去自己的风格?
ControlNet 的答案很简洁——把风格交给提示词,把结构交给控制信号。
ControlNet 通过额外的条件输入(结构提示)来引导 AI 的生成方向,同时保留模型的原生风格。这意味着你可以用一张参考图来控制生成的构图、透视、姿态,而最终出片的画风仍然由你的 Prompt 和底模决定。
在 Z-Image(ComfyUI)工作流中,这一能力通过 QwenImageDiffsynthControlnet 节点实现,配合 ImpactSwitch 节点即可在多种控制模式间自由切换。
二、三种控制模式详解
ControlNet 提供了多种预处理器(Preprocessor),每种提取的结构信息不同,适合不同的使用场景。本文聚焦最常用、最实用的三种:
深度估计(Depth)
Depth 预处理器通过单张输入图像估算每个像素的 3D 距离信息,生成一张灰度深度图——近处更亮,远处更暗。
它保护什么?
- 相机距离(景深关系)
- 大型物体的轮廓与体块
- 源图中的透视关系,包括那些"别扭"的透视角度
它不关心什么?
- 颜色、纹理、材质细节
- 人物的具体姿态(除非姿态影响了整体轮廓)
典型表现: 源图中的透视畸变会被保留,这正是 Depth 的特点——它忠实地传递空间结构,不做美学修正。
边缘检测(Canny)
Canny 预处理器提取图像中清晰、干净的轮廓线条,完全忽略内部纹理。
它保护什么?
- 物体的外轮廓和内部结构线
- 线条的走向与交点
它不关心什么?
- 颜色、明暗渐变、材质
- 深度信息和空间层次
关键特点: Canny 在中等强度下对线稿控制非常可靠,但在高强度下容易变脆(brittle)——线条过于生硬,模型"被迫"贴合每一条线,导致画面僵硬、细节失真。
姿态估计(Pose)
Pose 预处理器将人体映射为关节点和骨骼连线(OpenPose 格式),用彩色线条标注关键骨骼结构。
它保护什么?
- 人体的整体节奏感(身体韵律)
- 四肢的位置与角度
- 关节之间的相对关系
它不关心什么?
- 面部 likeness(不会保证"像某个人")
- 衣物的褶皱与细节
- 非人物体的结构
关键认知: Pose 控制的是"身体在空间中的节奏",而非"具体长什么样"。它非常适合角色姿态设计,但不要指望它解决面部相似度问题。
对比总表
| 特性 | Depth(深度) | Canny(线稿) | Pose(姿态) |
|---|---|---|---|
| 提取的信息 | 3D 距离/空间结构 | 轮廓线条 | 人体关节骨骼 |
| 最擅长 | 建筑、场景透视 | 线稿转绘、草图细化 | 人物姿态设计 |
| 保留透视? | ✅ 忠实保留 | ❌ 不关心透视 | ❌ 仅保留人体比例 |
| 忽略纹理? | ✅ | ✅ | ✅(仅关注人体) |
| 高强度风险 | 空间感过度固化 | 线条僵硬、画面变脆 | 姿态过正、不自然 |
| 推荐起始强度 | 0.5–0.6 | 0.4–0.6 | 0.5–0.7 |
| 非人物体有效? | ✅ | ✅ | ❌ |
三、何时使用哪种模式?
选 Depth 的场景
- 建筑/室内设计可视化:保留空间透视和物体比例关系
- 场景重建:从照片生成同一视角的不同风格渲染
- 产品渲染:保持产品与环境的深度关系
- 透视矫正需求低时(Depth 会保留源图透视,包括不理想的视角)
选 Canny 的场景
- 线稿上色/风格转换:将手绘草图转为成品
- 结构精确复刻:需要严格遵循轮廓线的场景
- 图标/LOGO 生成:需要精准边缘控制
- 从简单草图到精细出图的转换流程
选 Pose 的场景
- 角色概念设计:固定人物姿态,尝试不同风格/服装
- 同人创作:用参考姿态生成不同角色的同一动作
- 动态姿势设计:探索人物动作的多种变体
- 多角色场景构图:控制多个角色的站位和动作
决策流程图
需要控制什么?
├── 空间结构/透视 → Depth
├── 轮廓线条/草图 → Canny
└── 人物姿态/动作 → Pose
需要同时控制多个维度?
└── 组合使用(见第七节)
四、Depth 工作流(逐步指南)
节点连接
[LoadImage] → 参考图像输入
↓
[ControlNet Preprocessor: Depth] → 生成深度图
↓
[QwenImageDiffsynthControlnet]
├── 输入:深度图
├── strength: 0.5(起始值)
└── 输出:conditioning
↓
[VAEEncode] ← Prompt(风格描述)
↓
[KSampler]
├── positive: conditioning (来自 ControlNet)
├── negative: 负面提示词
└── model: 底模
↓
[VAEDecode] → [SaveImage]
关键参数
| 参数 | 推荐值 | 说明 |
|---|---|---|
| strength | 0.5 | 起始值,视需求调整 |
| start_step | 0.0 | 从采样开始就介入 |
| end_step | 0.8 | 在采样后期退出,保留模型自由 |
| preprocessor | Depth | MiDaS 或 ZoeDepth |
示例
输入: 一张室内照片
Prompt: cinematic lighting, modern interior design, warm tones, photorealistic, 8k
Strength: 0.55
效果: 输出保留了原始房间的空间布局和透视,但材质、灯光、风格完全由 Prompt 驱动,生成了一张电影级室内渲染。
调整经验:
- 将 strength 从 0.55 提升到 0.7,空间约束更强,但模型风格自由度下降
- 将 end_step 从 0.8 缩短到 0.6,模型有更多后期自由,风格更明显


五、Canny 工作流(逐步指南)
节点连接
[LoadImage] → 参考图像/线稿输入
↓
[ControlNet Preprocessor: Canny]
├── low_threshold: 100
└── high_threshold: 200
↓
[QwenImageDiffsynthControlnet]
├── 输入:Canny 边缘图
├── strength: 0.5(起始值)
└── 输出:conditioning
↓
[KSampler] → [VAEDecode] → [SaveImage]
Canny 阈值参数
| 参数组合 | 效果 | 适用场景 |
|---|---|---|
| low: 100, high: 200 | 标准边缘提取 | 通用场景 |
| low: 50, high: 100 | 更多细节线条 | 精细草图 |
| low: 150, high: 250 | 仅保留粗轮廓 | 简化线稿 |
示例
输入: 简单手绘角色草图
Prompt: masterpiece, best quality, anime style, detailed character, dynamic pose
Strength: 0.45
Canny 阈值: low 100, high 200
效果: 草图的轮廓被忠实保留,AI 在轮廓内部填充了精致的动漫风格细节——发丝、服装纹理、光影效果。
调整经验:
- strength = 0.4 时,模型有较大自由发挥空间,适合草图转绘
- strength > 0.7 时,线条约束过强,面部容易出现僵硬感
- 对于复杂线稿,适当降低 high_threshold 可减少噪音线条的干扰


多模式切换
使用 ImpactSwitch 节点,可以将同一 ControlNet 节点接入多个预处理器的输出,通过一个开关值动态切换:
[Depth Preprocessor] ─┐
[Canny Preprocessor] ├→ [ImpactSwitch] → [QwenImageDiffsynthControlnet]
[Pose Preprocessor] ┘
Switch Index = 0 → Depth, = 1 → Canny, = 2 → Pose
这样无需重新布线即可切换控制模式,大幅简化工作流。
六、Pose 工作流(逐步指南)
节点连接
[LoadImage] → 参考图像(含人物)
↓
[ControlNet Preprocessor: OpenPose]
├── 检测人体关节
└── 输出:彩色姿态图
↓
[QwenImageDiffsynthControlnet]
├── 输入:姿态图
├── strength: 0.6(起始值)
└── 输出:conditioning
↓
[KSampler] → [VAEDecode] → [SaveImage]
示例
输入: 一张运动员跑步的照片
Prompt: cyberpunk character, neon city background, dynamic running pose, futuristic outfit
Strength: 0.6
效果: 输出人物的奔跑姿态与参考图高度一致,但角色外观完全变成了赛博朋克风格——完全不同的服装、配色和背景。
调整经验:
- strength = 0.5:姿态约束较宽松,适合探索姿态变体
- strength = 0.6–0.7:标准范围,姿态还原度高且保持自然
- strength > 0.8:姿态过于"僵硬",人物像被固定住一样不自然
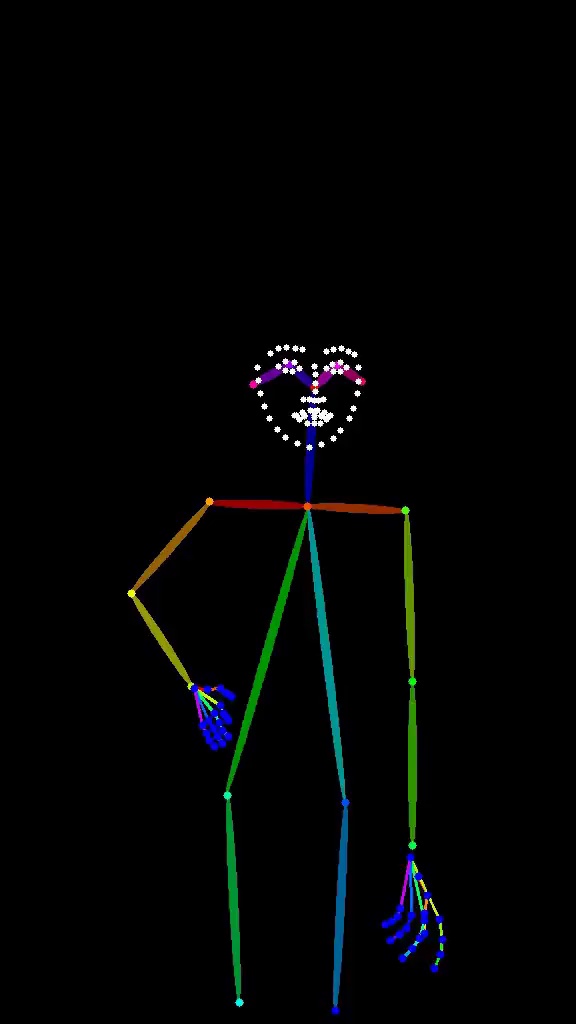

Pose 的局限性
- 面部不受控: Pose 只关注身体骨骼,不处理面部特征。如果需要面部控制,请搭配 IP-Adapter 或 Facial Restoration 节点
- 非人物体无效: Pose 对建筑、产品、动物等非人物体无作用
- 多人物场景: OpenPose 能检测多人,但关节可能交叉混乱。复杂多人场景建议手动清理姿态图
七、组合工作流
组合一:Pose + Inpaint(局部重绘)
这是角色创作中最实用的组合之一。
场景: 你有一个满意的角色全身姿态,但面部或服装需要调整。
[LoadImage] → [IP-Adapter / Face Restore] → 面部控制
↓
[OpenPose Preprocessor] → 姿态控制
↓
[QwenImageDiffsynthControlnet] (Pose, strength 0.6)
↓
[KSampler] with [LatentMask] → 局部采样
↓
[VAEDecode] → [SaveImage]
工作流步骤:
- 用 Pose 控制Net固定整体姿态(strength 0.6)
- 生成完整角色图像
- 在面部区域画遮罩(mask)
- 对遮罩区域进行局部重绘(inpaint),调整 facial features 或表情
- 姿态控制确保重绘后的面部仍然与身体姿态协调
组合二:多个 ControlNet 并行
Z-Image 支持同时使用多个 ControlNet 节点,叠加不同的结构约束。
[Depth Preprocessor] → [QwenImageDiffsynthControlnet] (strength 0.4)
[Canny Preprocessor] → [QwenImageDiffsynthControlnet] (strength 0.3)
↓ ↓
[Concat Conditioning] → [KSampler]
叠加原则:
- 每个 ControlNet 的 strength 单独设置,总和不应过高
- 推荐的总 strength 上限:1.0(超过则模型失去自由度)
- Depth + Canny 是经典组合:Depth 控制空间结构,Canny 控制轮廓线条
典型组合:
| 组合 | 场景 | 推荐强度分配 |
|---|---|---|
| Depth + Canny | 建筑/产品可视化 | Depth 0.4, Canny 0.3 |
| Pose + Depth | 角色在复杂场景 | Pose 0.5, Depth 0.3 |
| Pose + Canny | 角色线稿上色 | Pose 0.4, Canny 0.4 |
组合三:ControlNet + IP-Adapter
ControlNet 管结构,IP-Adapter 管风格/面部,两者互补:
[参考图A - 结构] → [ControlNet Preprocessor] → [ControlNet Node]
[参考图B - 风格/脸] → [IP-Adapter] → [Conditioning]
↓ ↓
[Concat] → [KSampler]
这样你可以用一张图控制构图,用另一张图控制风格或面部特征。
八、强度调优指南与进阶技巧
强度基准表
| Strength | 效果描述 | 适用场景 |
|---|---|---|
| 0.2–0.3 | 轻微引导 | 只需要一点点结构暗示 |
| 0.4 | 宽松控制 | 草图转绘,保留较多风格自由 |
| 0.5–0.6 | 基线推荐值 | 大多数场景的起点 |
| 0.7 | 强控制 | 需要较高结构还原度 |
| 0.8 | 精确锁定 | 需要严格遵循参考结构 |
| 0.9–1.0 | 极致约束 | 极易导致僵硬/伪影,慎用 |
调优流程
Step 1: 从 strength = 0.5 开始
Step 2: 生成 2-4 张,观察结构还原度和风格自由度的平衡
Step 3: 如果结构不够 → 每次 +0.1 上调
Step 4: 如果风格被压制 → 每次 -0.1 下调
Step 5: 找到平衡点后,微调 start_step 和 end_step
进阶技巧
1. 分阶段控制(start_step / end_step)
ControlNet 不必在整个采样过程中全程参与。通过控制介入时间段,可以实现更精细的效果:
start_step = 0.0, end_step = 0.6
→ ControlNet 在前 60% 采样阶段引导结构,后 40% 由模型自由发挥
start_step = 0.2, end_step = 0.8
→ 跳过最初 20%(让模型先建立大致方向),中间阶段介入
经验法则:
- 想要模型更多自由 → 缩短 end_step
- 想要结构更精确 → 延长 end_step,但不要超过 0.9
- 想让模型"先思考" → 延迟 start_step 到 0.1–0.2
2. 预处理后处理
预处理后的结构图(深度图、边缘图、姿态图)可以手动编辑后再输入 ControlNet:
- 深度图: 用灰度编辑器调整局部深度,修正不准确的区域
- Canny 图: 手动擦除不需要的线条,或补充缺失的轮廓
- 姿态图: 用 OpenPose Editor 调整关节位置,摆出参考图中没有的姿态
3. 多尺度处理
对于不同分辨率的输入,预处理效果会有差异:
- 小图(< 512px): 预处理精度下降,建议先放大再预处理
- 大图(> 1024px): 预处理精度高但计算量大,注意显存
- 最佳实践: 预处理到 1024px 左右,再送入 ControlNet
4. 常见问题排查
| 问题 | 可能原因 | 解决方案 |
|---|---|---|
| 输出与参考图完全无关 | strength 太低 / 预处理器选错 | 提高 strength 到 0.6,确认预处理器 |
| 画面僵硬、细节丢失 | strength 太高 | 降到 0.5–0.6,缩短 end_step |
| Canny 输出有噪点 | 阈值设置不当 | 调高 high_threshold |
| Pose 检测不到人物 | 人物太小/被遮挡 | 裁剪参考图,确保人物占主要区域 |
| Depth 透视不准确 | 输入图像本身透视模糊 | 使用更清晰的参考图 |
| 组合 ControlNet 冲突 | 总 strength 过高 | 降低各节点 strength,总和不超 1.0 |
5. 保存与复用
- 将调优好的 strength、start_step、end_step 参数记录下来
- 在 Z-Image 中,将整个工作流保存为模板(.png 工作流)
- 使用 ImpactSwitch 预配置多个模式,一键切换
总结
ControlNet 是 AI 图像生成中最强大的结构控制工具。掌握 Depth、Canny、Pose 三种核心模式,你就拥有了:
- Depth —— 空间的锚点,让 AI "看到"三维结构
- Canny —— 线条的骨架,让 AI "沿着"轮廓创作
- Pose —— 姿态的节奏,让 AI "理解"人体运动
记住核心原则:
Prompt 决定风格,ControlNet 决定结构,Strength 决定两者之间的平衡。
从 strength = 0.5 起步,逐步调整,找到每个场景的最佳平衡点。随着经验积累,你将能够精确控制 AI 生成的每一个细节,同时保持模型原生的艺术风格。
本文基于 Z-Image(ComfyUI)环境编写,核心节点为 QwenImageDiffsynthControlnet 和 ImpactSwitch。不同插件版本的参数名称可能略有差异,请以实际节点面板为准。