微软 VibeVoice-ASR:革命性的长音频语音识别模型
2026年1月21日,微软正式开源了 VibeVoice-ASR,这标志着自动语音识别(ASR)技术的重大进步。这个统一的语音转文本模型专为长音频处理而设计,在单次推理中提供前所未有的转录、说话人分离和时间戳标注能力。

什么是 VibeVoice-ASR?
VibeVoice-ASR 是微软研究院开发的最先进的语音识别模型。与传统 ASR 系统在处理长音频文件时的困难不同,VibeVoice-ASR 可以在单次推理中处理长达 60 分钟的连续音频,在整个录音过程中保持一致的说话人追踪和语义连贯性。
该模型通过将三个关键功能整合到一个统一系统中,实现了语音转文本技术的突破:
- 自动语音识别(ASR):将口语转换为文本
- 说话人分离:识别和追踪不同的说话人
- 时间戳标注:为每个话语提供精确的时间标记
这种整合消除了对独立处理流程的需求,显著提高了长音频转录任务的效率和准确性。
核心特性和能力
60分钟单次处理
VibeVoice-ASR 最令人印象深刻的特性之一是能够在单次处理中处理长达 60 分钟的连续音频。这一能力通过先进的架构设计实现,在 64K token 长度限制内运行,同时保持全局上下文感知。
传统 ASR 模型通常需要将长音频文件分割成较小的片段,这可能导致:
- 跨片段的上下文信息丢失
- 说话人识别不一致
- 转录质量碎片化
- 处理复杂度增加
VibeVoice-ASR 通过一次性处理整个音频文件解决了这些问题,确保一致的说话人追踪并在整个录音过程中保持语义连贯性。
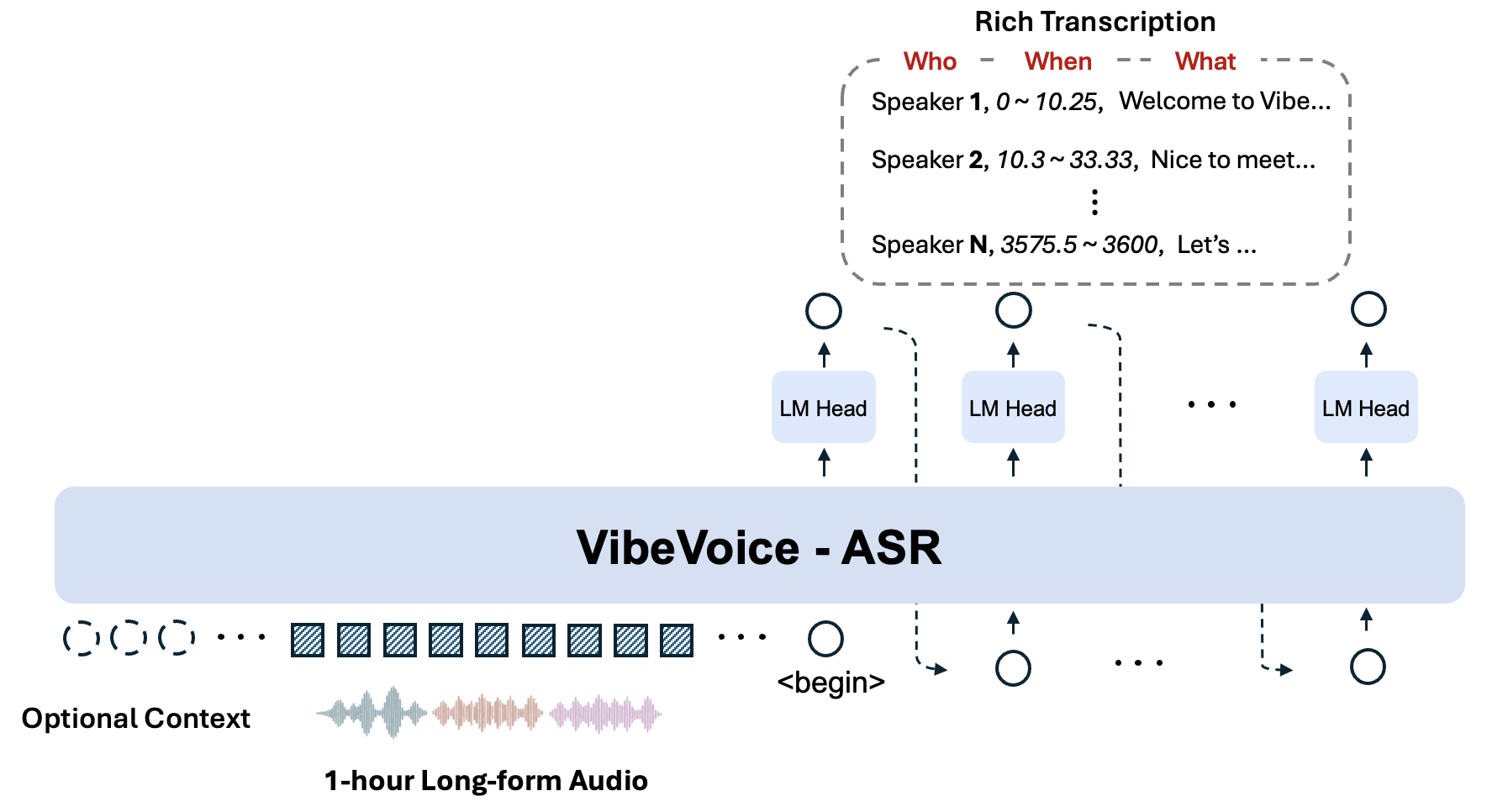
结构化转录输出(谁、何时、什么)
VibeVoice-ASR 生成丰富的结构化转录,回答三个基本问题:
- 谁:说话人识别和追踪
- 何时:每个话语的精确时间戳
- 什么:口语内容的准确转录
这种结构化输出格式对以下场景特别有价值:
- 会议转录和分析
- 访谈记录
- 播客和视频内容索引
- 法律和医疗转录
- 教育内容处理
该模型同时执行 ASR、说话人分离和时间戳标注,消除了后处理步骤的需求,减少了整体转录时间。
自定义热词支持
VibeVoice-ASR 包含强大的热词自定义功能,允许用户提供特定术语、名称或技术词汇,以提高特定领域内容的识别准确性。这对以下场景特别有用:
- 技术文档:确保专业术语的准确转录
- 商务会议:正确捕获公司名称、产品名称和行业术语
- 医疗转录:准确识别医学术语和药物名称
- 法律程序:正确转录法律术语和案例引用
- 学术内容:捕获技术术语、研究人员姓名和专业词汇
通过提供自定义热词,用户可以显著提高其特定领域的转录准确性,而无需进行模型微调或重新训练。
超低帧率处理
VibeVoice-ASR 使用连续语音分词器以超低 7.5 Hz 帧率运行。这种创新方法实现了:
- 长音频的高效处理
- 降低计算需求
- 更快的推理时间
- 更低的内存消耗
低帧率并不会影响准确性;相反,它允许模型在更高效地处理音频的同时保持更广泛的时间上下文。
技术规格
模型架构
VibeVoice-ASR 基于 Qwen2.5 架构构建,利用先进的语言模型能力进行语音理解。该模型使用语音增强语言模型(SALM)方法,结合了:
- 基础模型:Qwen2.5 基础
- 参数数量:90亿参数(部分来源显示为70亿变体)
- 张量类型:BF16(Brain Floating Point 16位)
- 格式:Safetensors,用于高效加载和部署
- 框架:下一个token扩散与LLM集成
这种架构使 VibeVoice-ASR 能够同时利用语音特定处理和通用语言理解,从而实现卓越的转录质量和上下文感知。
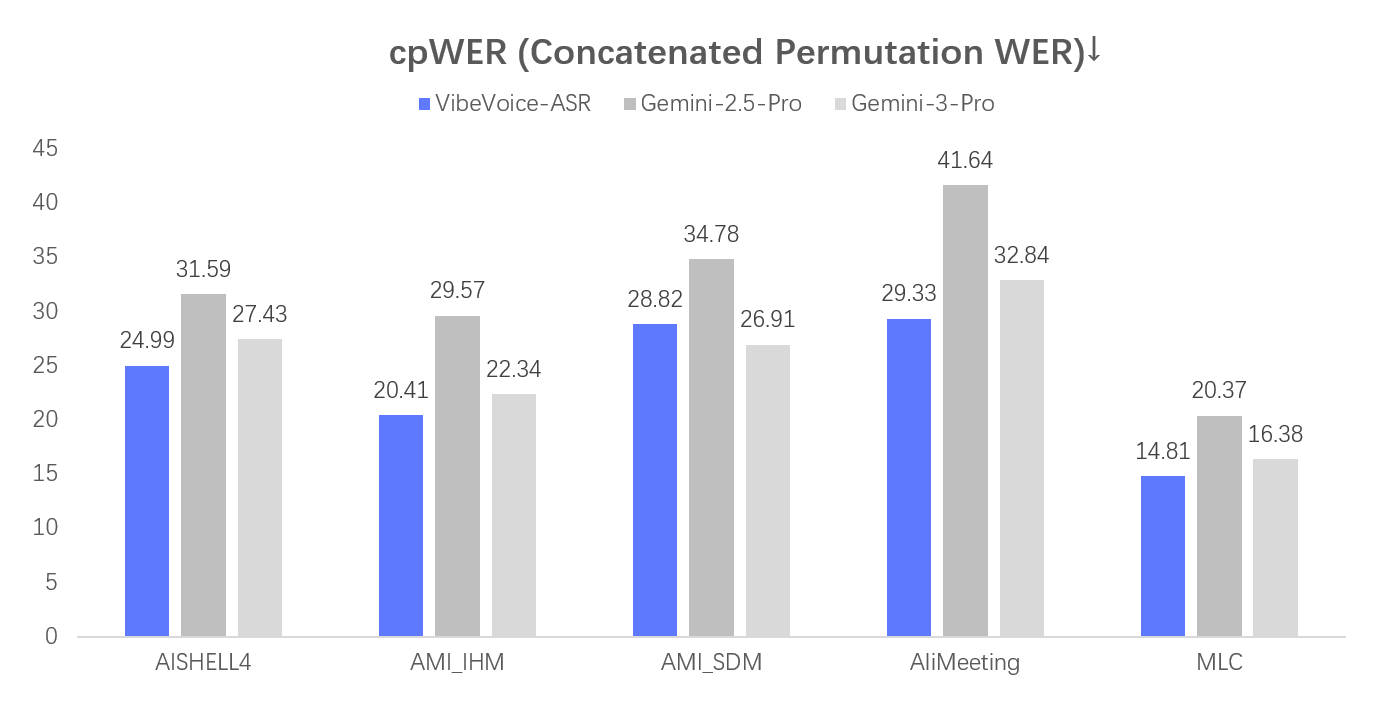
性能指标
VibeVoice-ASR 使用三个关键指标进行评估:
- DER(分离错误率):衡量说话人识别和分段的准确性
- cpWER(字符级音素词错误率):在字符级别评估转录准确性
- tcpWER(时间约束音素词错误率):评估转录准确性和时间对齐
根据基准测试结果,VibeVoice-ASR 在所有三个指标上都表现出竞争力,使其适合需要高准确性的生产用例。
硬件要求
运行 VibeVoice-ASR 需要大量的计算资源,因为其拥有 90 亿参数规模:
最低要求:
- GPU:至少 24GB VRAM 的 NVIDIA GPU(例如 RTX 3090、RTX 4090、A5000)
- 内存:32GB 系统内存
- 存储:20GB 用于模型权重和依赖项
- CUDA:CUDA 11.8 或更高版本
推荐配置:
- GPU:NVIDIA A100(40GB/80GB)或 H100 以获得最佳性能
- 内存:64GB 或更多用于处理多个音频文件
- 存储:SSD,50GB+ 可用空间
- CUDA:CUDA 12.0 或更高版本
对于生产部署,建议使用配备 A100 或类似 GPU 的云端 GPU 实例(AWS、Azure、Google Cloud),以确保一致的性能和可扩展性。
与竞品 ASR 模型的对比
VibeVoice-ASR vs. OpenAI Whisper
OpenAI 的 Whisper Large V3 一直是 ASR 领域的主导者,但 VibeVoice-ASR 提供了几个优势:
VibeVoice-ASR 优势:
- 原生支持 60 分钟单次处理
- 集成说话人分离,无需额外模型
- 内置高精度时间戳标注
- 支持自定义热词以提高特定领域准确性
- 针对长音频内容优化
Whisper 优势:
- 支持 100+ 种语言
- 在嘈杂环境中的鲁棒性已得到验证
- 多种模型大小适用于不同用例
- 广泛的社区支持和集成
使用场景建议:
- 选择 VibeVoice-ASR:长会议、访谈、播客和需要说话人识别的内容
- 选择 Whisper:多语言内容、嘈杂环境和边缘设备部署
VibeVoice-ASR vs. Deepgram Nova-2
Deepgram Nova-2 是一个以速度和准确性著称的商业 ASR 解决方案:
VibeVoice-ASR 优势:
- 开源且免费使用
- 集成说话人分离
- 更好地处理超长音频文件(60分钟)
- 包含自定义热词支持
Deepgram Nova-2 优势:
- 实时应用的更低延迟
- 具有高可用性的托管 API 服务
- 特定领域模型(医疗、金融等)
- 企业支持和 SLA
成本对比:
- VibeVoice-ASR:免费(仅自托管基础设施成本)
- Deepgram Nova-2:按使用付费,起价 $0.0043/分钟
VibeVoice-ASR vs. Google Chirp
Google 的 Chirp 模型是其 Cloud Speech AI 产品的一部分:
VibeVoice-ASR 优势:
- 开源,完全控制部署
- 无使用限制或配额
- 更适合隐私敏感应用
- 集成说话人分离
Google Chirp 优势:
- 广泛的语言支持(100+ 种语言)
- 具有自动扩展的托管服务
- 与 Google Cloud 生态系统集成
- 持续的模型更新
VibeVoice-ASR 快速入门
安装
可以使用官方 GitHub 仓库安装和部署 VibeVoice-ASR:
# 克隆仓库
git clone https://github.com/microsoft/VibeVoice.git
cd VibeVoice
# 安装依赖
pip install -r requirements.txt
# 从 Hugging Face 下载模型
# 模型将在首次使用时自动下载
基本使用示例
from vibevoice import VibeVoiceASR
# 初始化模型
model = VibeVoiceASR.from_pretrained("microsoft/VibeVoice-ASR")
# 加载音频文件
audio_path = "meeting_recording.wav"
# 执行带说话人分离的转录
result = model.transcribe(
audio_path,
enable_diarization=True,
enable_timestamps=True,
hotwords=["VibeVoice", "Microsoft", "ASR"]
)
# 访问结构化输出
for segment in result.segments:
print(f"[{segment.start:.2f}s - {segment.end:.2f}s]")
print(f"说话人 {segment.speaker}: {segment.text}")
高级配置
# 配置模型以获得最佳性能
config = {
"max_audio_length": 3600, # 60分钟(秒)
"beam_size": 5,
"language": "zh",
"enable_hotwords": True,
"diarization_threshold": 0.5
}
result = model.transcribe(audio_path, **config)
使用场景和应用
会议转录和分析
VibeVoice-ASR 在转录商务会议方面表现出色,提供:
- 多参与者讨论的准确说话人识别
- 便于导航和参考的精确时间戳
- 通过自定义热词支持技术术语
- 单次处理完成小时级会议的完整转录
优势:
- 自动生成会议纪要
- 可搜索的会议档案
- 行动项提取
- 合规性和记录保存
播客和视频内容索引
内容创作者可以利用 VibeVoice-ASR 进行:
- 为无障碍访问生成准确的字幕
- 创建可搜索的内容数据库
- 提取关键引用和亮点
- 实现跨平台的内容再利用
访谈记录
记者、研究人员和人力资源专业人员受益于:
- 访谈的逐字转录
- 多人访谈的说话人识别
- 便于引用验证的时间编码参考
- 支持特定领域术语
法律和医疗转录
专业转录服务可以利用 VibeVoice-ASR 进行:
- 法庭程序和证词
- 医疗咨询和患者访谈
- 合规文档
- 保密的本地处理
最佳实践以获得最佳结果
音频质量优化
要使用 VibeVoice-ASR 获得最佳转录准确性:
推荐的音频规格:
- 采样率:16 kHz 或更高
- 位深度:16位或24位
- 格式:WAV、FLAC 或高质量 MP3
- 声道:单声道或立体声
录音环境:
- 最小化背景噪音
- 使用优质麦克风
- 保持说话人与麦克风的一致距离
- 避免音频压缩伪影
有效使用热词
通过提供相关热词来最大化转录准确性:
hotwords = [
"VibeVoice-ASR",
"微软Azure",
"机器学习",
"神经网络",
"API端点"
]
result = model.transcribe(audio_path, hotwords=hotwords)
热词最佳实践:
- 包含公司名称、产品名称和品牌术语
- 添加特定于您领域的技术术语
- 包含专有名词(人名、地点)
- 保持热词列表集中(建议10-50个术语)
- 根据转录结果更新热词
性能优化
对于生产部署,考虑以下优化策略:
批处理:
- 并行处理多个音频文件
- 高效利用 GPU 内存
- 为大型工作负载实施队列管理
内存管理:
- 监控 GPU 内存使用
- 在处理会话之间清除缓存
- 使用混合精度(FP16/BF16)以加快推理速度
延迟降低:
- 预加载模型权重
- 使用模型量化以加快推理速度
- 为实时应用实施流式处理
局限性和注意事项
虽然 VibeVoice-ASR 提供了令人印象深刻的能力,但用户应该了解某些局限性:
当前局限性
语言支持:
- 主要专注于英语转录
- 与 Whisper 相比,多语言能力有限
- 非英语语言可能需要微调
计算要求:
- 需要高端 GPU 硬件(24GB+ VRAM)
- 不适合边缘设备或低资源环境
- 大规模部署的基础设施成本显著
音频长度:
- 针对最多 60 分钟的音频进行优化
- 更长的录音可能需要分段
- 极长文件的性能可能会下降
推荐使用场景
VibeVoice-ASR 最适合:
- 企业会议转录
- 专业内容创作
- 研究和学术应用
- 法律和医疗文档
- 任何需要说话人分离和长音频处理的场景
未来发展和路线图
作为一个开源项目,VibeVoice-ASR 预计将随着社区贡献和微软的持续开发而发展:
预期改进:
- 扩展语言支持
- 降低计算要求
- 增强实时处理能力
- 提高嘈杂环境的准确性
- 特定领域的微调能力
结论
微软 VibeVoice-ASR 代表了语音识别技术的重大进步,特别是在长音频处理方面。其处理 60 分钟连续音频并集成说话人分离和时间戳标注的能力,使其成为企业应用、内容创作者和专业转录服务的绝佳选择。
关键要点:
- VibeVoice-ASR 在带说话人识别的长音频转录方面表现出色
- 该模型需要大量 GPU 资源,但能提供高质量结果
- 自定义热词支持可提高特定领域的准确性
- 开源特性提供了部署的灵活性和控制权
- 最适合需要结构化转录输出的应用
对于寻求强大的开源 ASR 解决方案来处理长音频的组织和开发者,VibeVoice-ASR 提供了商业服务的有力替代方案。虽然它需要大量的计算资源,但准确性、说话人分离和自定义能力的结合使其成为现代语音识别领域的宝贵工具。
资源和链接
- 官方 GitHub 仓库:https://github.com/microsoft/VibeVoice
- Hugging Face 模型:https://huggingface.co/microsoft/VibeVoice-ASR
- 交互式演示:https://aka.ms/vibevoice-asr
- 文档:https://github.com/microsoft/VibeVoice/blob/main/docs/vibevoice-asr.md
- 联系方式:VibeVoice@microsoft.com