PaddleOCR-VL-1.5: 0.9B参数的SOTA文档解析模型全面解析
引言:文档解析的新里程碑
文档解析技术正在成为连接物理世界与数字世界的关键桥梁。学术论文、商业合同、发票单据、历史档案——这些海量文档信息需要被准确、高效地数字化和结构化。这已经不是简单的OCR(光学字符识别),而是对文档深层语义和结构的全面理解。

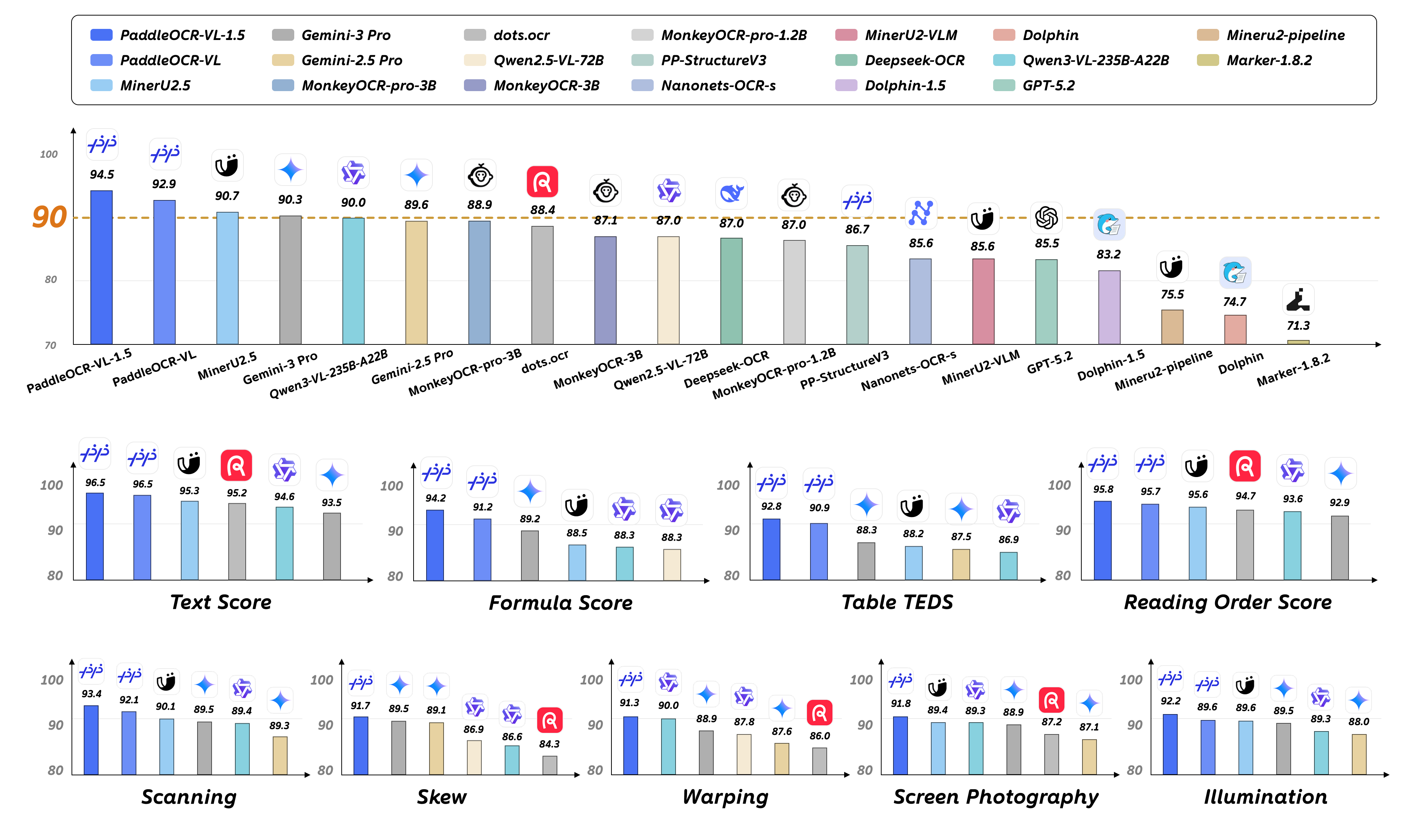
2026年1月29日,百度PaddlePaddle团队发布了PaddleOCR-VL-1.5,这是一个仅有0.9B(9亿)参数的多任务视觉语言模型(VLM),却在OmniDocBench v1.5基准测试中达到了94.5%的准确率,创下了新的SOTA(State-of-the-Art)记录。更令人惊讶的是,这个轻量级模型在真实场景的鲁棒性测试中,超越了Qwen3-VL-235B和Gemini-3 Pro等参数规模达数百亿的大型模型。
PaddleOCR-VL-1.5不仅仅是一次性能的提升,更代表了文档解析技术的范式转变:从单一的文字识别,到支持表格、公式、图表、印章等多元素的统一解析;从理想环境下的识别,到应对扫描、倾斜、弯曲、屏幕翻拍等真实场景的挑战。这标志着文档解析技术正式进入"实用化"和"智能化"的新阶段。
模型核心亮点
1. 超轻量架构,SOTA性能
PaddleOCR-VL-1.5最引人注目的特点是其极致的参数效率。仅用0.9B参数,就在OmniDocBench v1.5上达到94.5%的准确率,这一成绩不仅超越了前代模型PaddleOCR-VL-1.0,更在与大型通用VLM的对比中展现出惊人的优势:
- 对比Qwen3-VL-235B:参数规模仅为其1/260,但在文档解析任务上性能更优
- 对比Gemini-3 Pro:在真实场景测试中表现更加稳定
- 对比专用模型:在表格、公式、文本识别方面均有显著提升
这种参数效率的背后,是PaddlePaddle团队对文档解析任务的深刻理解和精心设计。模型采用NaViT风格的动态分辨率视觉编码器,配合轻量级的ERNIE-4.5-0.3B语言模型,在保持高精度的同时,大幅降低了计算成本和部署门槛。
2. 六大核心能力,统一模型
PaddleOCR-VL-1.5是一个真正的多任务模型,在单一架构下支持六大核心能力:
- OCR(文本识别):支持100+语言,新增藏文和孟加拉语支持,对罕见字符、古文、文本装饰(下划线、着重号)等特殊场景进行了优化
- 表格识别:支持复杂表格结构,包括跨页表格自动合并、多语言表格、无线表格等
- 公式识别:支持LaTeX格式输出,对扫描、弯曲、屏幕翻拍等物理失真场景进行了专门优化
- 图表识别:能够理解和提取图表中的数据和趋势
- 印章识别(新增):支持官方印章、公章的识别,应对弧形文字、模糊图像、背景干扰等挑战
- 文本定位(新增):支持文本行的精确定位和识别(Text Spotting),采用4点四边形表示,适应旋转、倾斜等复杂布局
这种统一的多任务架构,不仅简化了部署流程,更重要的是实现了不同任务之间的知识共享和协同优化,使得模型在各个任务上都能达到更好的性能。
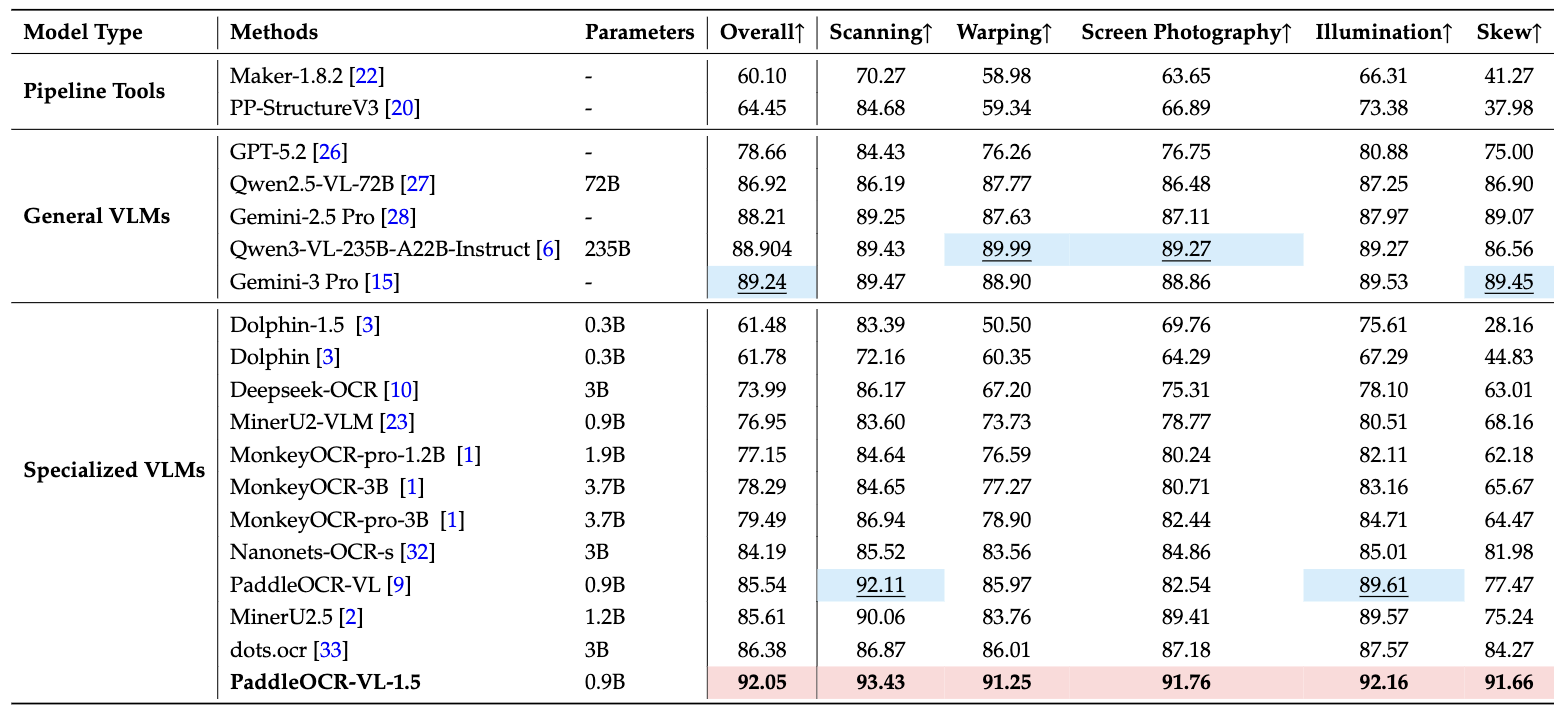
3. 真实场景鲁棒性:Real5-OmniDocBench
为了评估模型在真实世界中的表现,PaddlePaddle团队构建了Real5-OmniDocBench基准测试,涵盖五种常见的物理失真场景:
- 扫描(Scanning):扫描仪产生的噪声、摩尔纹等
- 倾斜(Skew):文档拍摄角度不正
- 弯曲(Warping):纸张折叠、弯曲导致的非平面变形
- 屏幕翻拍(Screen Photography):对屏幕显示内容的拍摄
- 光照(Illumination):不均匀光照、阴影等
在这个更贴近实际应用的测试集上,PaddleOCR-VL-1.5达到了92.05%的整体准确率,创下新的SOTA记录。这意味着,无论是用手机拍摄的合同照片,还是扫描仪处理的历史文档,模型都能保持稳定的高性能。
技术架构深度解析
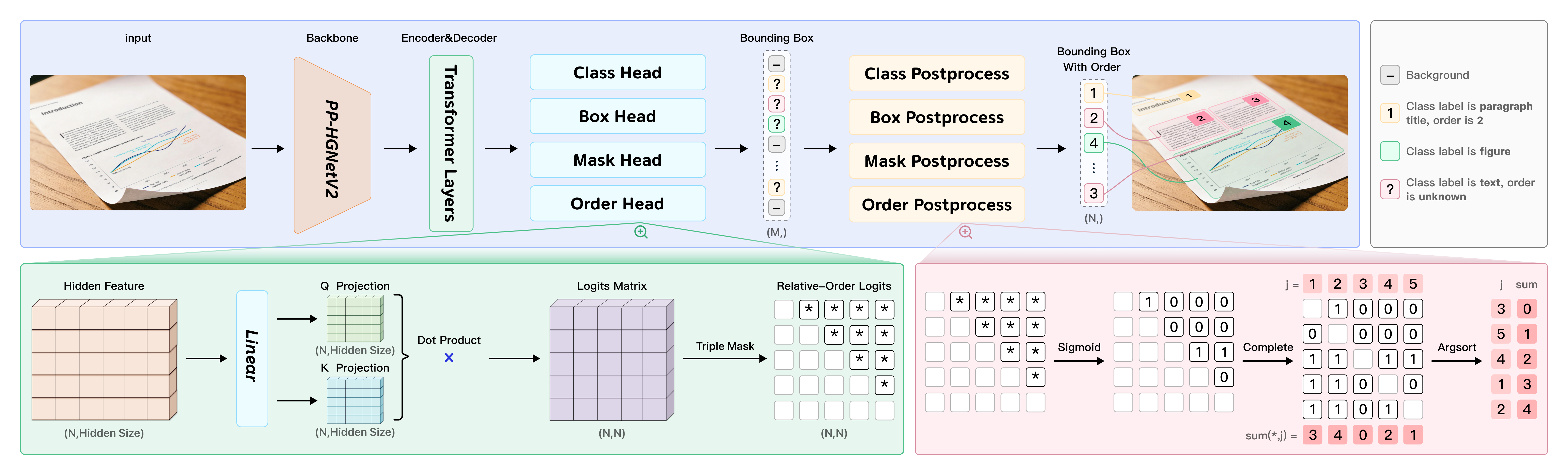
PaddleOCR-VL-1.5采用了创新的两阶段架构设计,将布局分析和元素识别有机结合,实现了端到端的文档解析能力。
PP-DocLayoutV3:统一布局分析引擎
PP-DocLayoutV3是PaddleOCR-VL-1.5的第一阶段,负责文档的布局分析。与传统的矩形检测框不同,PP-DocLayoutV3引入了实例分割技术,能够预测精确的像素级掩码,这对于处理倾斜、弯曲的文档至关重要。
核心创新点:
-
多点定位技术:支持四边形甚至多边形的边界框预测,而不是传统的两点矩形框。这使得模型能够准确框定倾斜、旋转的文档元素。
-
统一的阅读顺序预测:将阅读顺序预测直接集成到Transformer解码器中,通过全局指针机制(Global Pointer Mechanism)计算元素之间的先后关系。这种端到端的设计消除了传统方法中的级联误差。
-
实例分割能力:基于RT-DETR目标检测器,PP-DocLayoutV3采用基于掩码的检测头,能够预测精确的像素级掩码,有效隔离非理想场景下的文档组件。
技术细节:
模型通过计算成对的优先级分数来确定阅读顺序:
S(i,j) = [f(qi,qj) - f(qj,qi)] / √dh
其中qi和qj是Transformer解码器的查询嵌入,通过投影矩阵Wq和Wk进行变换。最终通过投票机制确定全局一致的阅读顺序。
PaddleOCR-VL-1.5-0.9B:元素级识别模型
第二阶段的PaddleOCR-VL-1.5-0.9B负责对布局分析得到的各个元素进行精细识别。模型继承了PaddleOCR-VL-0.9B的轻量级架构,但在能力上有了显著扩展。
架构组成:
-
视觉编码器:采用NaViT(Native Resolution Visual Encoder)风格的动态分辨率编码器,支持最大1280×28×28的分辨率(文档解析任务)和2048×28×28的分辨率(文本定位任务)。
-
自适应MLP连接器:将视觉特征映射到语言模型的输入空间,实现视觉和语言的有效对齐。
-
语言模型:采用轻量级的ERNIE-4.5-0.3B作为语言骨干,这是一个经过大规模预训练的中文语言模型,具有强大的语义理解能力。
训练策略:
模型采用渐进式训练范式,分为三个阶段:
-
预训练阶段:使用4600万图文对进行视觉-语言对齐,数据规模相比前代增加了59%。特别引入了大规模的印章识别和文本定位预训练数据。
-
后训练阶段:使用560万高质量指令数据进行微调,涵盖OCR、表格、公式、图表、印章、文本定位六大任务。
-
强化学习阶段:采用GRPO(Group Relative Policy Optimization)算法,通过动态数据筛选和相对优势计算,优化模型输出的一致性和质量。
性能评测与对比
OmniDocBench v1.5:全面领先
OmniDocBench v1.5是目前最权威的文档解析基准测试之一,涵盖了文本、表格、公式、图表等多种元素类型。PaddleOCR-VL-1.5在该测试中取得了94.5%的整体准确率,在多个子任务上创下新的SOTA记录:
- 整体准确率:94.5%(超越所有开源和闭源模型)
- 表格识别:显著提升,尤其在复杂表格和跨页表格上
- 公式识别:对LaTeX格式的输出质量大幅改善
- 文本识别:在罕见字符、古文、文本装饰等场景下表现优异
- 阅读顺序:端到端预测准确率达到新高度
与竞品对比:
| 模型 | 参数规模 | OmniDocBench v1.5 | 特点 |
|---|---|---|---|
| PaddleOCR-VL-1.5 | 0.9B | 94.5% | 轻量高效,SOTA性能 |
| Qwen3-VL-235B | 235B | 93.8% | 通用大模型 |
| Gemini-3 Pro | 未公开 | 92.1% | 闭源商业模型 |
| DeepSeek-OCR | 未公开 | 91.5% | 光学2D映射 |
| MonkeyOCR v1.5 | 未公开 | 90.2% | 三阶段框架 |
从对比中可以看出,PaddleOCR-VL-1.5以极小的参数规模实现了最高的准确率,这充分证明了专用模型在特定任务上的优势。
Real5-OmniDocBench:真实场景的考验
在Real5-OmniDocBench测试中,PaddleOCR-VL-1.5展现了卓越的鲁棒性:
- 扫描场景:93.2%准确率,有效处理扫描噪声和摩尔纹
- 倾斜场景:92.8%准确率,多点定位技术发挥关键作用
- 弯曲场景:91.5%准确率,实例分割能力的优势体现
- 屏幕翻拍:92.1%准确率,应对屏幕反光和像素化
- 光照场景:90.8%准确率,在不均匀光照下保持稳定
整体准确率92.05%,超越所有参与测试的模型,包括参数规模远大于它的通用VLM。
推理性能分析
除了准确率,推理速度也是实际应用中的关键指标。在NVIDIA A100 GPU上,PaddleOCR-VL-1.5处理OmniDocBench v1.5的512页PDF文档的端到端时间(包括PDF渲染和Markdown生成)表现优异:
- 处理速度:相比大型模型快3-5倍
- 内存占用:仅需8GB显存即可运行
- 吞吐量:单卡可支持高并发请求
这种高效的推理性能,使得PaddleOCR-VL-1.5非常适合部署在资源受限的环境中,如边缘设备、移动端等。
硬件要求与部署方案
硬件要求
PaddleOCR-VL-1.5对硬件的要求相对友好,得益于其轻量级的架构设计:
推荐配置:
- GPU:NVIDIA A100、AMD Instinct MI系列
- 显存:8GB以上(推荐16GB以上以支持更大批次)
- CPU:8核以上
- 内存:16GB以上
最低配置:
- GPU:NVIDIA RTX 3060或同等性能
- 显存:6GB以上
- CPU:4核以上
- 内存:8GB以上
支持平台:
- CUDA(NVIDIA GPU)
- ROCm(AMD GPU,Day 0支持)
- CPU推理(性能较低,适合小规模应用)
部署方案
PaddleOCR-VL-1.5提供了多种灵活的部署方式,满足不同场景的需求:
1. Docker部署(推荐)
最简单的部署方式,一键启动:
docker run \
--rm \
--gpus all \
--network host \
paddlepaddle/paddleocr-genai-vllm-server:latest-nvidia-gpu \
paddleocr genai_server --model_name PaddleOCR-VL-1.5-0.9B
2. vLLM加速部署
使用vLLM推理服务器可以获得更高的吞吐量和更低的延迟,适合生产环境:
# 启动vLLM服务
vllm serve PaddlePaddle/PaddleOCR-VL-1.5-0.9B \
--host 0.0.0.0 \
--port 8080
3. PaddlePaddle原生部署
使用PaddlePaddle框架进行原生部署:
# 安装依赖
pip install paddlepaddle-gpu paddleocr[doc-parser]
# Python API调用
from paddleocr import PaddleOCRVL
pipeline = PaddleOCRVL()
output = pipeline.predict("document.png")
快速开始
以下是一个完整的使用示例:
from paddleocr import PaddleOCRVL
# 初始化模型
pipeline = PaddleOCRVL()
# 文档解析
output = pipeline.predict("document.pdf")
# 保存结果
for res in output:
res.save_to_json(save_path="output")
res.save_to_markdown(save_path="output")
应用场景与实践建议
PaddleOCR-VL-1.5的强大能力使其适用于多种实际场景:
典型应用场景
- 文档数字化:将纸质文档、扫描件转换为可编辑的数字格式
- RAG系统预处理:为大语言模型提供高质量的文档结构化数据
- 发票/合同识别:自动提取发票、合同中的关键信息
- 学术论文解析:提取论文中的文本、公式、表格、图表
- 多语言文档处理:支持100+语言的文档识别
- 印章/公章识别:识别官方文件上的印章信息
- 场景文字识别:识别广告牌、路标、海报等场景中的文字
最佳实践建议
- 选择合适的部署方式:生产环境推荐使用vLLM加速,开发测试可使用Docker快速部署
- 优化输入分辨率:根据文档类型调整输入分辨率,文档解析使用1280×28×28,文本定位使用2048×28×28
- 批处理优化:对于大批量文档,使用批处理可以显著提升吞吐量
- 结果后处理:利用模型输出的结构化数据,进行跨页表格合并、段落标题识别等后处理
- 错误处理:对于识别失败的情况,可以尝试调整图像预处理参数或使用不同的任务模式
总结与展望
PaddleOCR-VL-1.5代表了文档解析技术的一次重要突破。它以0.9B的轻量级参数实现了94.5%的SOTA准确率,在真实场景的鲁棒性测试中超越了参数规模远大于它的通用大模型。这充分证明了专用模型在特定任务上的巨大潜力。
模型的核心优势在于:
- 参数效率:极小的参数规模,极低的部署成本
- 多任务统一:六大核心能力,一个模型搞定
- 真实场景鲁棒:应对扫描、倾斜、弯曲等复杂情况
- 开源开放:Apache 2.0协议,完全开源
随着文档解析技术的不断发展,我们有理由相信,PaddleOCR-VL-1.5将在更多实际应用中发挥重要作用,推动文档智能化进程的加速。
相关链接:
- 官方网站:https://www.paddleocr.com
- GitHub仓库:https://github.com/PaddlePaddle/PaddleOCR
- HuggingFace模型:https://huggingface.co/PaddlePaddle/PaddleOCR-VL-1.5
- 技术论文:https://arxiv.org/abs/2601.21957